
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 혼공
- 자바스크립트
- javascript
- Block
- 혼자_공부하는_머신러닝+딥러닝
- ML
- 엘카데미후기
- 무료코딩
- 인공지능
- 혼공학습단
- 속성
- 엘리스아카데미
- js
- 코딩이벤트
- 엘리스코딩
- 엘카데미이벤트
- p태그
- border
- A태그
- CSS
- 혼공머신
- 엘리스출석챌린지
- html
- 머신러닝
- 태그
- 엘리스
- 딥러닝
- 엘카데미
- 선택자
- Margin
Archives
- Today
- Total
jinseon's log
혼동 행렬 (Confusion Matrix) 본문
분류 평가 지표
- 혼동 행렬 (Confusion Matrix)
- confusion_matrix(Y_true, X_pred) : Confusion_matrix 값을 nd.ndarray로 반환
- sklearn 라이브러리
- from sklearn.metrics import confusion_matrix
- Y_true
- test_Y : test_Y 에 대한 혼동 행렬
- train_Y : train_Y 에 대한 혼동 행렬
- X_pred
- pred_test : test_X 에 대한 예측 데이터
- pred_train : train_X 에 대한 예측 데이터
- load_breast_cencer() : 유방암 유무 판별 데이터 함수
- sklearn 라이브러리
- from sklearn.datasets import load_breast_cancer
- X, Y = load_breast_cancer(return_X_y = True)
- X (Feature) : 30개의 환자 데이터
- Y (Label) : 0 음성(악성), 1 양성(정상)
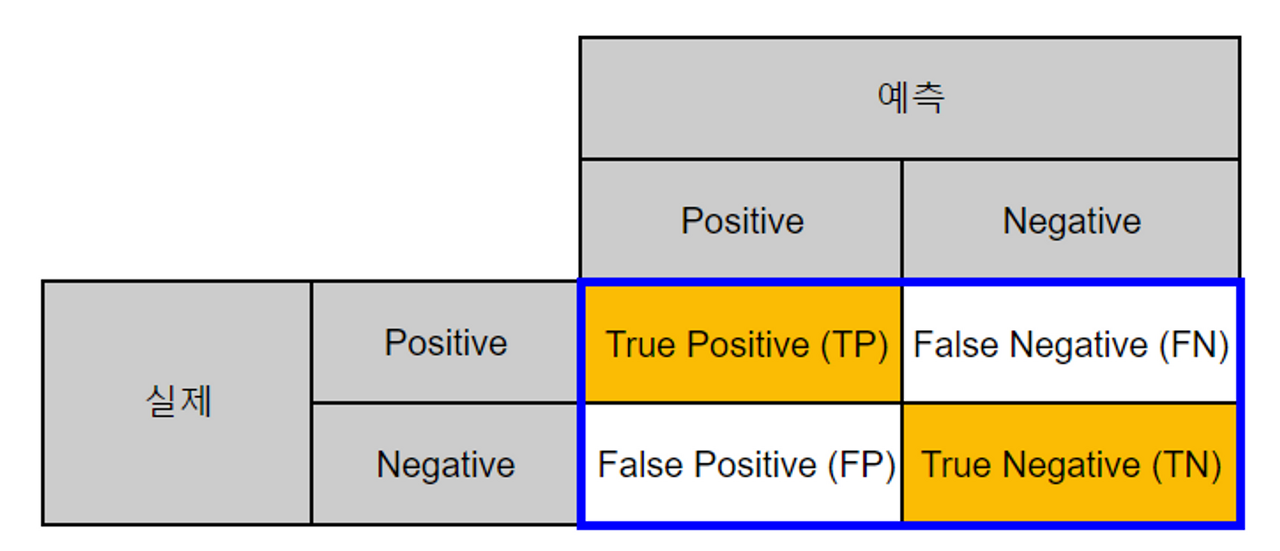
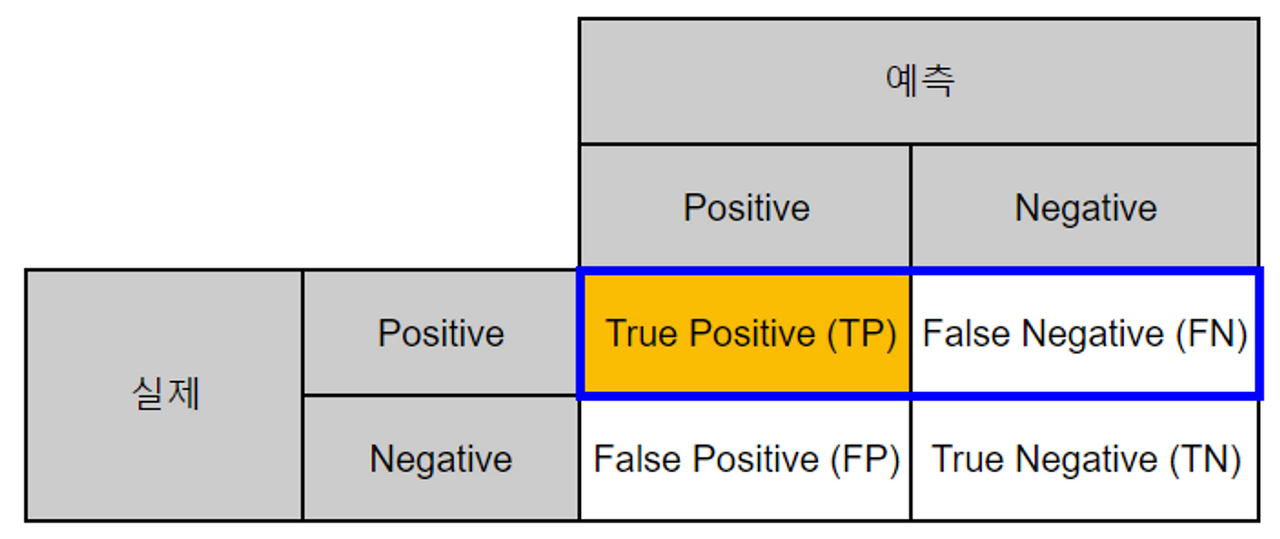
- 분류 모델의 성능을 평가하기 위해 가장 **기본적인 지표들을 계산**하는 행렬
- confusion_matrix(Y_true, X_pred) : Confusion_matrix 값을 nd.ndarray로 반환

- Positive == 0, Negative == 1
- True Positive (TP) : 실제 Positive == 예측 Positive
- True Negative (TN) : 실제 Negative == 예측 Negative
- False Positive (FP) : 실제 Negative ≠ 예측 Positive ⇒ 1형 오류
- False Negative (FN) : 실제 Positive ≠ 예측 Negative ⇒ 2형 오류
- 정확도 (Accuracy)
- **DTmodel.score(X_true, Y_true) : X_true 에 대한 정확도 계산**
- sklearn 라이브러리
- from sklearn.metrics import confusion_matrix
- DTmodel : 의사결정나무 모델 초기화 후 학습
- X_true
- test_X : 평가용 실제값
- train_X : 학습용 실제값
- Y_true
- test_Y: 평가용 예측값
- train_Y : 학습용 예측값
- 전체 데이터 중 **제대로 분류된 데이터 비율**
- 모델이 얼마나 정확하게 분류하는지를 나타냄
- 분류 모델의 **주요 평가 방법**
- **클래스 비율이 불균형** 할 경우, 평가 지표의 **신뢰성을 잃을 수 있음**
- **DTmodel.score(X_true, Y_true) : X_true 에 대한 정확도 계산**

- 정밀도 (Precision)
- **precision_score(Y_true, X_true) : Y_true 에 대한 정밀도 계산**
- sklearn 라이브러리
- from sklearn.metrics import precision_score
- Y_true
- test_Y: 평가용 데이터
- train_Y : 학습용 데이터
- X_true
- test_X : 평가용 데이터 예측값
- train_X : 학습용 데이터 예측값
- Negative 가 중요한 경우
- ex. 스팸 메일 판결
- Positive : 스팸, Negative : 일반
- 일반 메일을 스팸 메일로 잘못 예측(FP) 했을 경우 중요한 메일을 전달받지 못함
- ex. 스팸 메일 판결
- **precision_score(Y_true, X_true) : Y_true 에 대한 정밀도 계산**
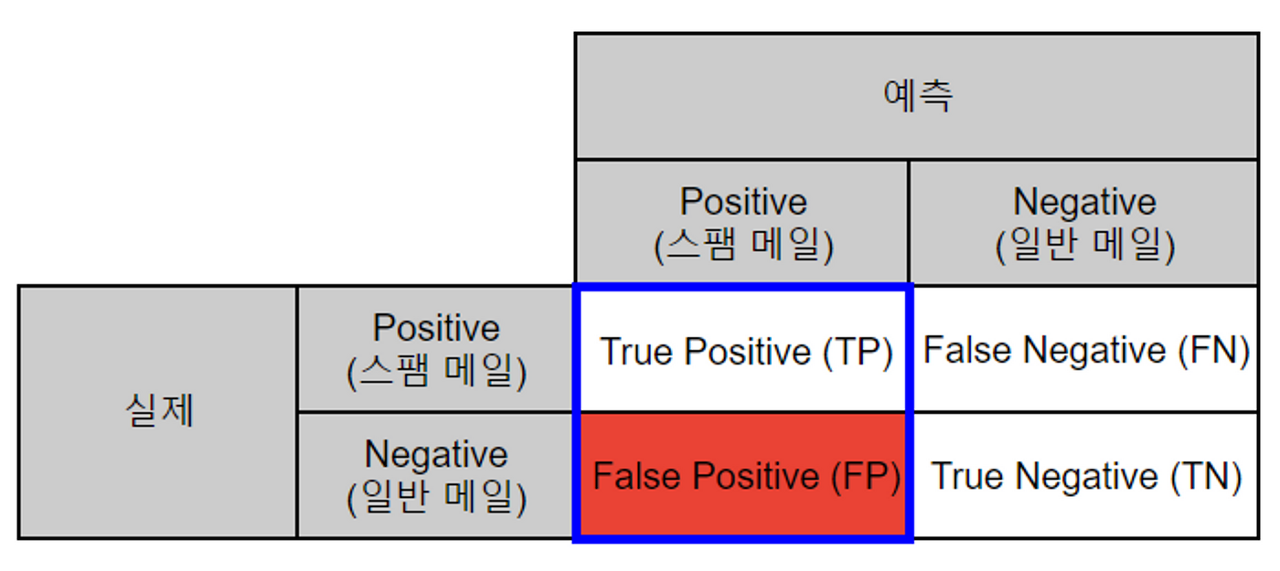
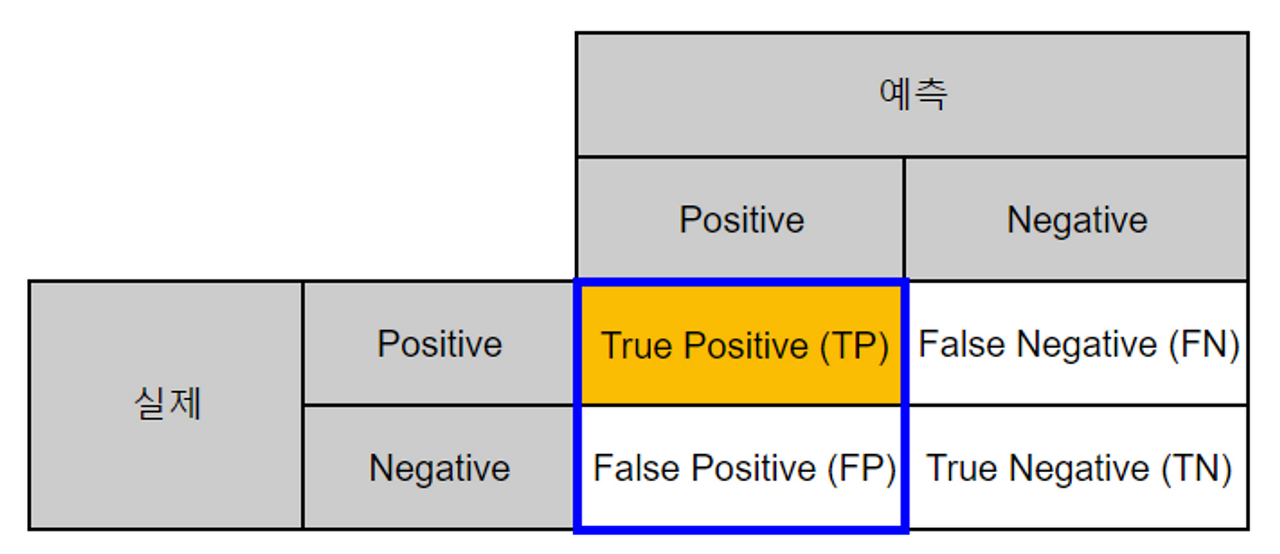
- **모델이 Positive 라고 분류한 데이터 중에서 실제로 Positive 인 데이터 비율**
- 실제로 Negative 인 데이터를 Positive **(FP)라고 판단 하면 안되는 경우 사용**되는 지표

- 재현율(Recall, TPR)
- **recall_score(Y_true, X_true) : Y_true 에 대한 재현율 계산**
- sklearn 라이브러리
- from sklearn.metrics import recall_score
- Y_true
- test_Y: 평가용 데이터
- train_Y : 학습용 데이터
- X_true
- test_X : 평가용 데이터 예측값
- train_X : 학습용 데이터 예측값
- Positive 가 중요한 경우
- ex. 악성 종양 여부 판결
- Positive : 악성 종양, Negative : 양성 종양
- 악성 종양을 양성 종양으로 잘못 예측(FN) 했을 경우 제 때 치료 받지 못해 생명 위급
- ex. 악성 종양 여부 판결
- **recall_score(Y_true, X_true) : Y_true 에 대한 재현율 계산**
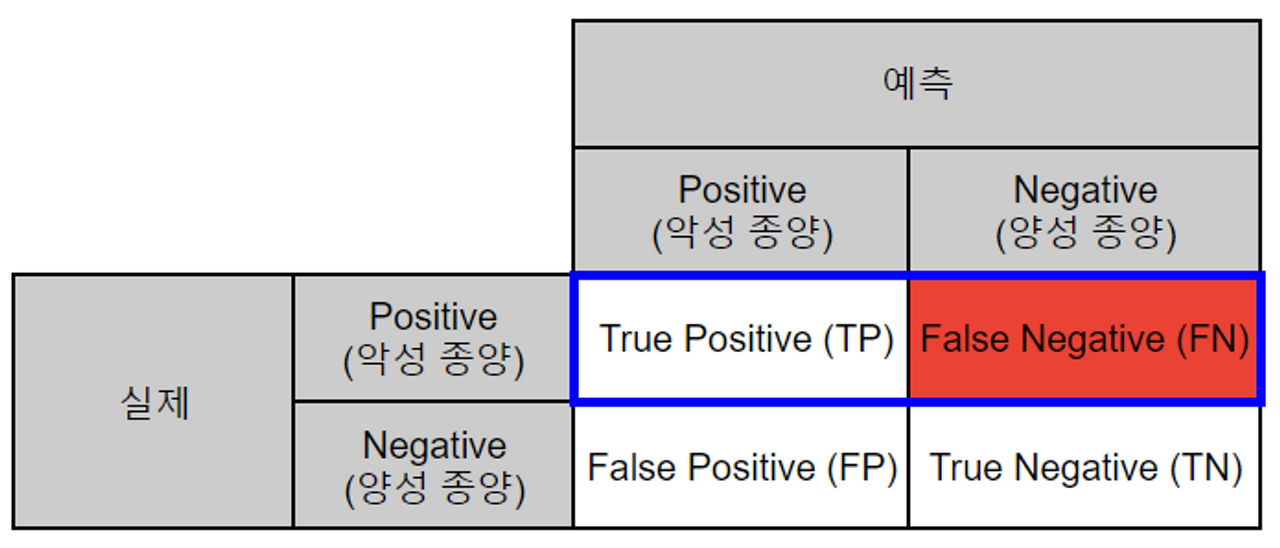
- **실제로 Positive 인 데이터 중에서 모델이 Positive 로 분류한 데이터 비율**
- 실제로 Positive 인 데이터를 Negative **(FN)라고 판단하면 안되는 경우 사용**되는 지표

- 분류 목적에 따른 지표
- 분류 결과를 전체적으로 보고 싶다 → 혼동 행렬 (Confusion Matrix)
- 정답을 얼마나 잘 맞췄는가 → 정확도 (Accuracy)
- FP 또는 FN 의 중요도가 높다 → 정밀도 (Precision), 재현율 (Recall)
'ML & DL' 카테고리의 다른 글
| [DL] CNN - AlexNet (2012) (2) | 2022.12.08 |
|---|
'ML & DL' Related Articles
more

Comments