
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 엘리스아카데미
- Margin
- 엘카데미후기
- 무료코딩
- CSS
- 엘카데미이벤트
- 혼공학습단
- 혼자_공부하는_머신러닝+딥러닝
- 혼공머신
- 인공지능
- javascript
- html
- border
- 혼공
- 엘리스코딩
- 딥러닝
- p태그
- 자바스크립트
- 엘카데미
- 태그
- 속성
- 엘리스
- 코딩이벤트
- 머신러닝
- js
- ML
- Block
- 선택자
- 엘리스출석챌린지
- A태그
- Today
- Total
jinseon's log
03 지도학습 (Supervised Learning) 본문
머신러닝은 크게 세 가지 카테고리로 나뉨
1) 지도학습 (Supervised Learning)
2) 비지도학습 (Unsupervised Learning)
3) 강화학습 (Reinforcement Learning)
👩🏻🏭 지도학습 (Supervised Learning)
- 정답을 알려주면서 학습 하는 것
- input과 output 간의 관계를 설명하는 방법론 중 가장 대표적인 방법
✔ Regression

- x : Input - 집의 특성들
- p : 변수의 개수
- 관측치 (observation) : 각각의 변수에 대해서 실제로 관측을 통해서 획득한 결과, Bedrooms 3, 2, 2 ...
- n : 관측치의 개수
📍 input 데이터의 경우 n*p matrix, 행렬 형태를 띠고 있는 경우가 많음
- y : Output - continuous (연속적인 수치), target, 부동산 가격
✔ Classification

- x : Input - 동물 이미지
- 관측치 (observation) : 이미지 하나하나
📍 Input은 테이블 형태의 데이터 혹은 이미지, 텍스트 등의 데이터가 될 수 있다.
🤔 이미지(관측치)마다 output이 카테고리로 정의 되어 있는 것이 이미지 분류 시 데이터 형태
- y : Output - class (범주형)
✔ Generalization Error and Hyperparameter
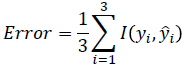
- I : 지시 함수 (Indicator function)
- yi, yi^가 같을 경우 0, 틀릴 경우 1로 틀린 개수가 많은 수록 값이 커짐

- 학습 오차 (Training error) : 학습시키는 데이터 내에서 발생한 오차
- 예측 오차 (Validation error, Generalization error) : 학습할 때 사용하지 않았던 데이터에 대해서 발생한 예측 데이터 오차
📍 전통적인 머신러닝 방법론에서 나타나는 error 패턴
- 모형이 복잡해질 수록 학습 오차는 줄어들고, 일반화 예측 오차는 좀 줄어들다가 다시 커짐
- 모델 복잡성 (model complexity) : 함수가 변동이 크고 디테일한가 혹은 단순하게 선을 만들어 내는가로 나뉨
- 모델 복잡성을 결정하는 데에는 hyperparameter가 영향을 줌
- 과소적합 (Under-fitting) : 모형이 단순해서 데이터의 전체 패턴을 표현하지 못함
- 과적합 (Over-fitting) : 너무 복잡해서 학습 데이터의 패턴에만 몰두를 했기 때문에 일반화가 잘 되지 않음
📍 예측 오차가 최소가 되는 적절한 모형을 찾아야함
'ML & DL > K-MOOK' 카테고리의 다른 글
| 04 Machine Learning Pipeline (0) | 2022.11.22 |
|---|---|
| 02 LinearRegression (0) | 2022.11.21 |
| 01 인공지능과 머신러닝 개요 (2) | 2022.11.21 |


